I’ve been messing around with LLM pre-training during my batch at the Recurse Center, mostly seeing how much I can squeeze out of limited compute. Most people training language models from scratch follow the same recipe: stack some Transformer blocks, throw AdamW at it, drop in flash attention, and call it a day. That works fine, but it’s also boring, and I wanted to see whether borrowing ideas from neighboring fields would actually help.
The borrowed idea I ended up exploring most was U-Net’s skip connections, and they translated to language modeling better than I expected.
Why U-Net?
U-Net is everywhere in computer vision. It was originally built for biomedical image segmentation, and now it’s the default architecture for anything with spatial hierarchies. The core idea is the skip connection. Early layers capture fine details, later layers capture the big picture, and you mix them back together so the output gets to use both.
Language has hierarchies too. Characters build into words, words into phrases, phrases into sentences. So I figured the skip-connection pattern might apply to a Transformer if I treated layer depth as a stand-in for spatial depth.
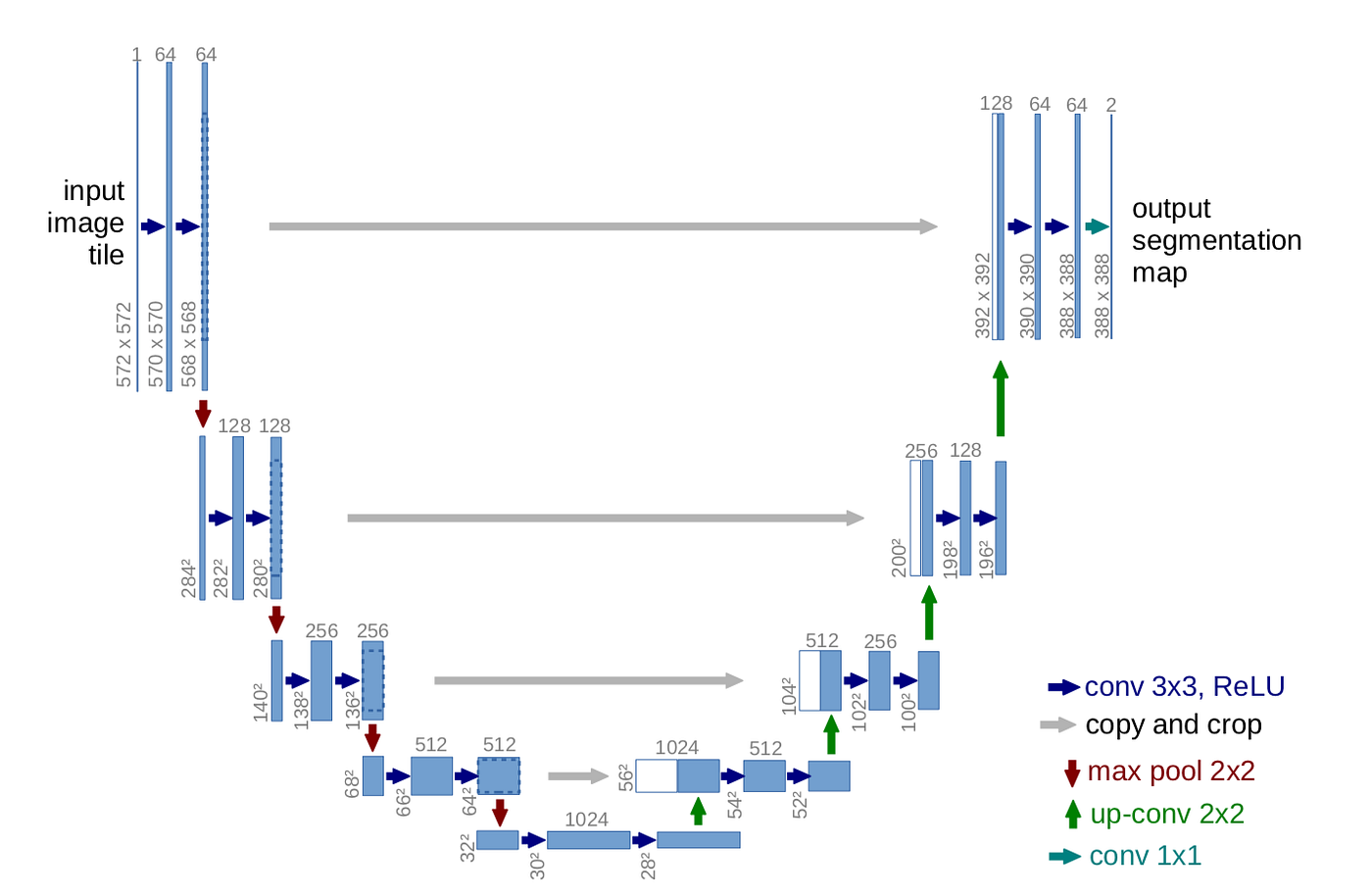
The setup is straightforward. I used 16 Transformer layers, split in half. Layers 1 through 8 store their activations on the way “down,” and layers 9 through 16 mix those stored activations back in on the way “up” via learned gates.
Each gate is a parameter per dimension, initialized at 0.1. The mixing rule is about as simple as it could be:
\[\text{output} = \text{gate} \times \text{skip} + (1 - \text{gate}) \times \text{current}\]
The network learns how much to rely on earlier features versus later ones at each layer. In practice, the gates converge to different values across layers. Some end up relying heavily on the skip connections (gate around 0.7), while others barely use them (gate around 0.1).
Here’s the core implementation:
1 | class GatedMixer(nn.Module): |
The training loop stores activations from the first 8 layers, then mixes them into the upper 8 layers in reverse order. Layer 9 gets mixed with layer 8’s output, layer 10 with layer 7, and so on, just like a standard U-Net.
Not all layers are equal
One thing that became obvious during training is that not all layers want the same attention mechanism. Early layers care about local patterns, like which words sit next to each other and basic syntactic relationships. Later layers care about context that spans the whole sequence.
For layers 1 through 8, I used sliding window attention. The mechanism is standard multi-head attention, but each query position only attends to a 256-token window around itself, the way Longformer does it. The reduced window saves memory and matches what early layers actually use.

A token at position \(i\) can only attend to positions in \([i - 256, i]\). You lose some long-range dependencies in those layers, which is fine for now, since the network is still building up local representations and the global view comes in the upper half.
For layers 9 through 16, I switched to multi-query attention (MQA). Instead of each attention head getting its own key and value projections, all heads share a single \(K\) and \(V\). It sounds odd at first, but it works well in practice, and the KV cache shrinks dramatically as a result. That last point is what makes it especially useful for inference.

With 8 heads and d_model=1024, standard MHA needs 8
separate K/V projections of 128 dimensions each. MQA shares one K and
one V across all heads. For 512 tokens, that’s roughly an 8× reduction
in KV cache memory.
Both attention types use RoPE for positional embeddings. Instead of adding position encodings to the input, RoPE rotates the Q and K vectors based on position. The nice thing about it is that relative positions get encoded directly into the dot product.

The rotation is computed using sine and cosine functions:
\[\text{freq}_{j} = \frac{1}{10000^{2j/d}}\]
\[\text{RoPE}(x, \text{pos}) = \begin{pmatrix} x_{1} \\ x_{2} \\ \vdots \end{pmatrix} \odot \begin{pmatrix} \cos(\text{pos} \cdot \text{freq}) \\ \cos(\text{pos} \cdot \text{freq}) \\ \vdots \end{pmatrix} + \text{rotate\_half}(x) \odot \begin{pmatrix} \sin(\text{pos} \cdot \text{freq}) \\ \sin(\text{pos} \cdot \text{freq}) \\ \vdots \end{pmatrix}\]
RoPE generalizes to longer sequences than you trained on. If you train on 512 tokens and want to do inference at 1024, RoPE handles that better than learned positional embeddings, which tend to break or degrade outside the training range.
Letting activation functions learn
The FFN blocks use squared ReLU, which is just \(\text{ReLU}(x)^2\). There’s a paper showing it works better than regular ReLU for language models, with some explanation involving the quadratic term and gradient flow. I’m not fully convinced by the explanation, but the empirical effect does seem to be there.
That made me wonder why the exponent should be hardcoded at 2 if the squaring is what’s doing the work. So I made it a learnable parameter and let the network decide:
1 | class SquaredReLUFFN(nn.Module): |
During training, some layers settled on \(\alpha \approx 2.3\), others stayed near 2.0, and a few drifted down to about 1.8. The fact that the network ended up choosing per-layer exponents that don’t all agree with each other is a small piece of evidence that the learnable version is doing something the fixed version can’t.
I also varied the FFN expansion ratio by layer:
- Layers 1-8: 4× expansion (4096 hidden for
d_model=1024). - Layers 9-16: 2.5× expansion (2560 hidden).
The intuition is that early layers are extracting features and benefit from more capacity, while later layers do more abstract aggregation and can get away with less.
Making it actually run
Architecture is one thing. Making it train without taking forever is another. A 16-layer Transformer with a hidden size of 1024 is not lightweight, and the optimizations around it ended up mattering as much as the architectural changes themselves.
The first one was mixed precision with bfloat16. Forward and backward in bf16, gradients accumulated in fp32. That alone roughly doubles throughput on modern GPUs:
1 | with torch.amp.autocast(device_type='cuda', dtype=torch.bfloat16): |
The reason I went with bf16 instead of fp16 is that bf16 has the same exponent range as fp32 (8 bits) and just less mantissa precision (7 bits versus 23). You don’t get the overflow headaches that fp16 hits in attention softmax and similar places. Float16 has more precision but a much narrower range, so most of the time you spend in fp16 ends up being spent debugging gradient explosions.
NVIDIA’s Transformer Engine goes further by using FP8 for attention. The memory savings are large. The KV cache drops to roughly half of what bf16 needs, which let me push batch sizes higher and gain another 30 to 40% throughput on top:
1 | if self.use_fp8 and te is not None: |
The caveat is that FP8 only really pays off on Hopper-class GPUs (H100 and newer). On older hardware the quantization noise eats most of the win.
Flash Attention is
non-negotiable at this point. Instead of materializing the full
attention matrix, which is \(O(n^2)\)
in memory, it computes attention in blocks and fuses the operations.
PyTorch ships it under scaled_dot_product_attention:
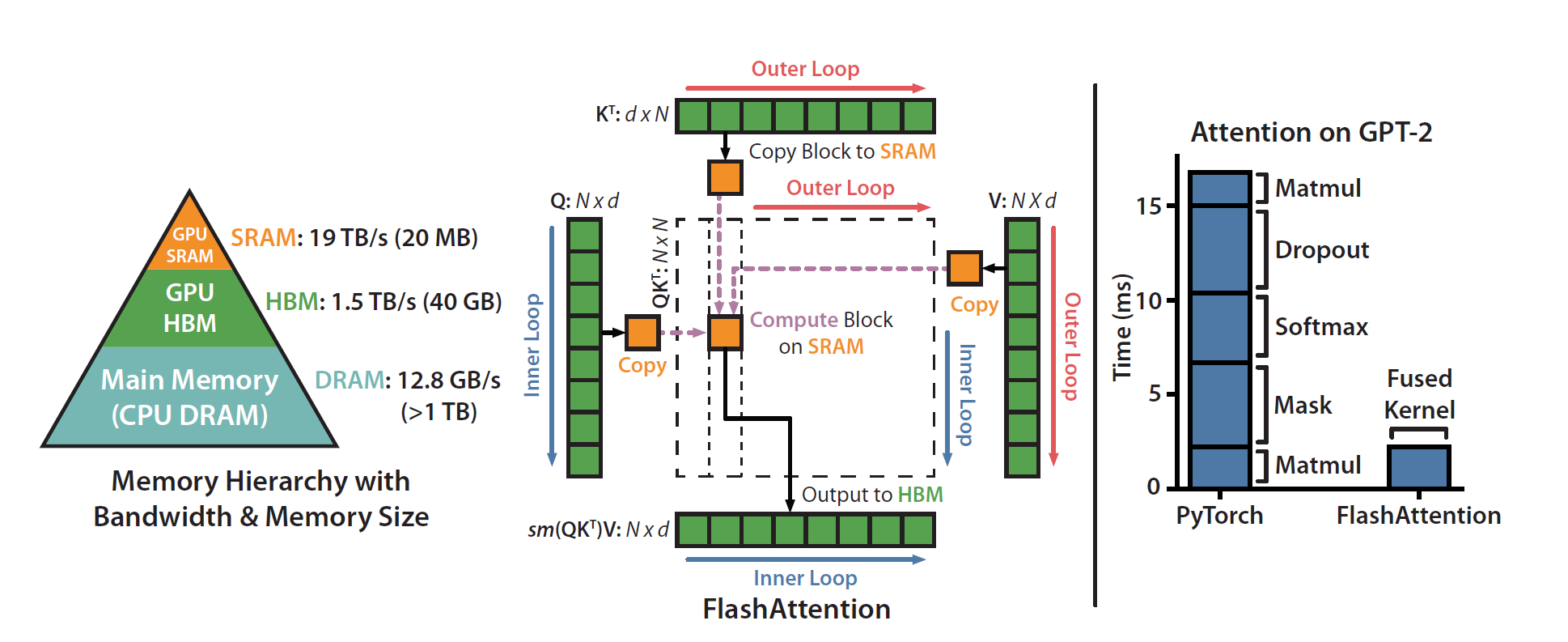
For my batch sizes, attention memory dropped by 5 to 8×, and end-to-end speed picked up by roughly 2 to 3×.
The annoying part is that Flash Attention can’t handle arbitrary attention masks, so for the sliding window attention in layers 1-8 I had to fall back to standard attention. It was slower than I’d have liked, but the window was small enough that it didn’t kill the budget.
Two PyTorch one-liners that helped more than I expected:
1 | torch.backends.cuda.matmul.allow_tf32 = True |
TF32 (TensorFloat-32) is NVIDIA’s intermediate format for matrix multiplications, with fp32-style range and reduced precision (10 mantissa bits instead of 23). It’s transparent to your code, you just enable it and the GEMMs get faster. I measured a 15 to 20% speedup on H100s.
cuDNN benchmarking auto-tunes convolution algorithms. It costs a few seconds at startup and picks the fastest kernel for whatever shapes you’re actually running.
torch.compile
is one of the best things that came out of PyTorch 2.0. It JIT-compiles
your model, fuses operations, and reduces kernel launches:
1 | model = torch.compile(model, mode='reduce-overhead', dynamic=True) |
mode='reduce-overhead' optimizes for fewer kernel
launches, which takes longer to compile but is worth it for training.
dynamic=True handles variable batch sizes, which I needed
because of gradient accumulation. The first iteration is painfully slow
while it compiles, and some operations don’t compile cleanly, but the
steady-state speedup was around 20 to 30%, which I’ll happily take.
With 16 layers, activation memory adds up fast. Gradient checkpointing trades compute for memory by recomputing activations during the backward pass instead of storing them:
1 | if self.gradient_checkpointing and (i % self.checkpoint_every == 0): |
I checkpointed every layer. That cut activation memory by roughly 70% and let me run bigger batches. The recompute overhead was about 20% slower per iteration, which was a fine trade for the headroom.
Optimizer choices
I tried Muon, which has been getting some attention recently. It’s a second-order optimizer in the same family as Shampoo, but easier to implement. It works on preconditioned gradients rather than raw gradients. For 1D parameters (biases, layer-norm scales), it falls back to AdamW:
1 | optimizer = MuonWithAuxAdam([ |
Not everything in the network should learn at the same speed, so I used per-block learning rates:
- Embeddings: 2e-3 (highest, since sparse updates can handle it).
- Layers 1-8: 8e-4 (local features, change fairly quickly).
- Layers 9-16: 6e-4 (global features, want more stability).
- LM head: 4e-4 (lowest, since pushing it higher makes the logits explode).
These came from a fair amount of trial and error. Early layers seem to learn local patterns easily and tolerate larger steps. Later layers do more abstract aggregation and want to be more conservative.
For the schedule, I used linear warmup for 1000 steps followed by cosine decay down to 10% of the peak LR. The formulas:
During warmup (\(t < t_{\text{warmup}}\)):
\[\eta(t) = \eta_{\max} \cdot \frac{t}{t_{\text{warmup}}}\]
After warmup (\(t \geq t_{\text{warmup}}\)):
\[\eta(t) = \eta_{\min} + \frac{1}{2}(\eta_{\max} - \eta_{\min}) \left(1 + \cos\left(\pi \frac{t - t_{\text{warmup}}}{t_{\text{total}} - t_{\text{warmup}}}\right)\right)\]
The warmup keeps things from exploding early, when random weights produce wild gradients. The cosine decay helps the optimizer converge cleanly toward the end of training.
VRAM was tight, so I couldn’t fit really large batches. The workaround was to accumulate gradients over two micro-batches before stepping, which doubles the effective batch size for free as far as memory is concerned:
1 | for micro_step in range(2): |
Just remember to divide the loss by the number of accumulation steps so the gradients stay scaled correctly.
How training went
I trained on Wikipedia and OpenWebText, about 10B tokens, for 50,000 steps total.
Loss converged smoothly with no weird spikes, which means the LR schedule and gradient clipping were doing their job.
The warmup is visible in the first 1000 steps, then it’s all cosine decay. The different per-block learning rates stay proportional to each other throughout.
Throughput climbed during the first few thousand steps as
torch.compile warmed up, then stabilized around 12k tokens
per second.
The U-Net gates evolved the way I’d hoped during training:
Layers 9 and 10, near the start of the up-path, learned to rely on skip connections heavily, with gates ending up around 0.5 to 0.6. Layers 14 through 16, near the output, kept their gates lower at 0.1 to 0.25, suggesting they trust their own features more than the early activations.
Memory stayed comfortably under the 80GB limit. Without gradient checkpointing and FP8, I’d have been pushing 55 to 65GB and stuck with much smaller batches.
What actually helped
Once I’d run the whole thing through a few times, a clearer picture emerged of which optimizations earned their keep.
The U-Net skip connections gave roughly a 5% improvement in loss. That’s not enormous, but the gates learned different per-layer values rather than collapsing to a uniform setting, so the network was clearly using them rather than ignoring them.
The mixed attention (MHA in the lower half, MQA in the upper half) didn’t change training speed much, but inference was about 15% faster because the KV cache shrunk significantly with MQA.
Layer-wise learning rates were a bigger win than I’d expected. I went in thinking maybe 2 or 3% improvement and ended up with around 8%. The embedding layer in particular really wants the higher LR.
FP8 attention was the biggest engineering win. It gave 35% more throughput, with the KV cache memory savings letting me double the batch size.
torch.compile was a roughly 25% speedup once the first
iteration finished compiling. That’s basically free.
Gradient checkpointing reduced activation memory by 70%, which mattered more than the 20% slower iterations cost. Without it I couldn’t have fit the model at a reasonable batch size at all.
Together, all of this let me train a 300M parameter model on a single H100 in days instead of weeks. Nothing record-breaking, but plenty for experimentation.
Things that flopped
Not everything worked.
Auxiliary loss at layer 8. I thought I could help the down-path learn better representations by adding a second LM head halfway through and supervising it with the same target. The loss weight kept shrinking to zero during training, and the auxiliary head ended up contributing nothing.
Bigger sliding windows. I tried 512 and 1024. They didn’t improve the loss and made things noticeably slower. 256 was the sweet spot for this model size.
Fancy gate initializations. I tried 0.5, 0.0, and per-dimension learnable gates. They all converged to about the same place. Initializing at 0.1 worked fine.
Stochastic depth. Randomly dropping layers (DropPath style) didn’t help. It might pay off for much deeper models, but at 16 layers it just hurt convergence.
Code
Full implementation is in my llm repo. Key files:
model/transformer.py: Hybrid U-Net Transformer architecture.model/attention.py: MHA and MQA with FP8 support.model/ffn.py: Squared ReLU with learnable exponent.train/loop.py: Training loop with all the optimizations.train/optim.py: Muon optimizer and learning rate schedules.
It’s not production-ready (no distributed training, no proper checkpointing, plenty of rough edges), but as a research codebase it does the job.
What’s next
A few directions I want to explore from here.
The obvious one is scaling. Does the U-Net pattern still help at 1B+ parameters, or does it become a wash? Pipeline parallelism and tensor parallelism would both come into play, since a model that size doesn’t fit on a single GPU.
Tokenization is another direction. I’m using a basic BPE tokenizer right now, and the byte-level work looks worth a serious look. Better tokenization tends to give you a free improvement at the input.
Mixture of experts is on the list too. Replacing some FFNs with MoE layers could help with the capacity-versus-speed tradeoff, especially in the upper half of the network where the layers are doing more abstract work.
Quantization-aware training is the last one. Training in FP8 from the start, rather than quantizing afterwards, has some support in the literature, but I haven’t actually tried it yet.
Closing thoughts
This project was a useful reminder that LLM architectures aren’t a solved problem. Almost everyone is using the same basic Transformer because it works, but there’s still a lot of room to borrow ideas from neighboring fields. Some of those ideas turn out to be wrong, and some of them turn out to be right, and you can’t always tell ahead of time which will be which.
The performance engineering ended up mattering as much as the
architecture. FP8 attention, torch.compile, gradient
checkpointing, and layer-wise learning rates are not exciting
research-wise, but they were the difference between weeks of training
and days. I’d rather have all of them than any individual architectural
trick.
If you’re doing LLM pre-training on limited compute, the ordering I’d
suggest is to enable mixed precision and torch.compile
first, since they’re the easiest wins. Add Flash Attention and FP8 if
your GPU supports them. Trade speed for memory with gradient
checkpointing where you need to fit larger batches. Tune learning rates
per layer if you have the time. Then start trying weirder architectural
ideas. The worst case for those is that you learn something about why
the standard Transformer is shaped the way it is, which is also
useful.