
I started my sabbatical pretty GPU poor. Going from “whatever compute I needed at Apple” to “my MacBook” was a real drop. Then I walked into the Recurse Center hub in NYC for the first time, and someone casually mentioned they had “a couple of GPUs” sitting around.
That got my attention.
The catch was that the hardware was not homogeneous. RC had a couple of NVIDIA GeForce GTX TITAN X cards, and I’d brought my M4 Max MacBook with Apple Silicon. Different vendors, different drivers, different memory architectures, different runtimes. The classic “how do I get all of these to cooperate?” problem.
That’s when I remembered Ray exists.
The heterogeneous hardware problem
Training across mismatched hardware is a real and growing thing. Maybe your company acquired a team that brought their own GPUs. Maybe your provider just released a new SKU with different math. Maybe you’re at RC trying to use whatever’s on the shelf. Either way, you eventually run into it.
My specific situation:
- MacBook M4 Max, Apple Silicon with MPS (Metal Performance Shaders).
- RC machines, NVIDIA GeForce GTX TITAN X with CUDA. There were two of them, named Mercer and Crosby, because RC names its machines.
Traditional distributed training frameworks struggle with this kind of mix. NCCL (NVIDIA’s communication library) and Apple’s MPS don’t speak the same language at the transport level. Ray sidesteps the problem by sitting one layer above the metal and coordinating between hardware types through a shared abstraction.
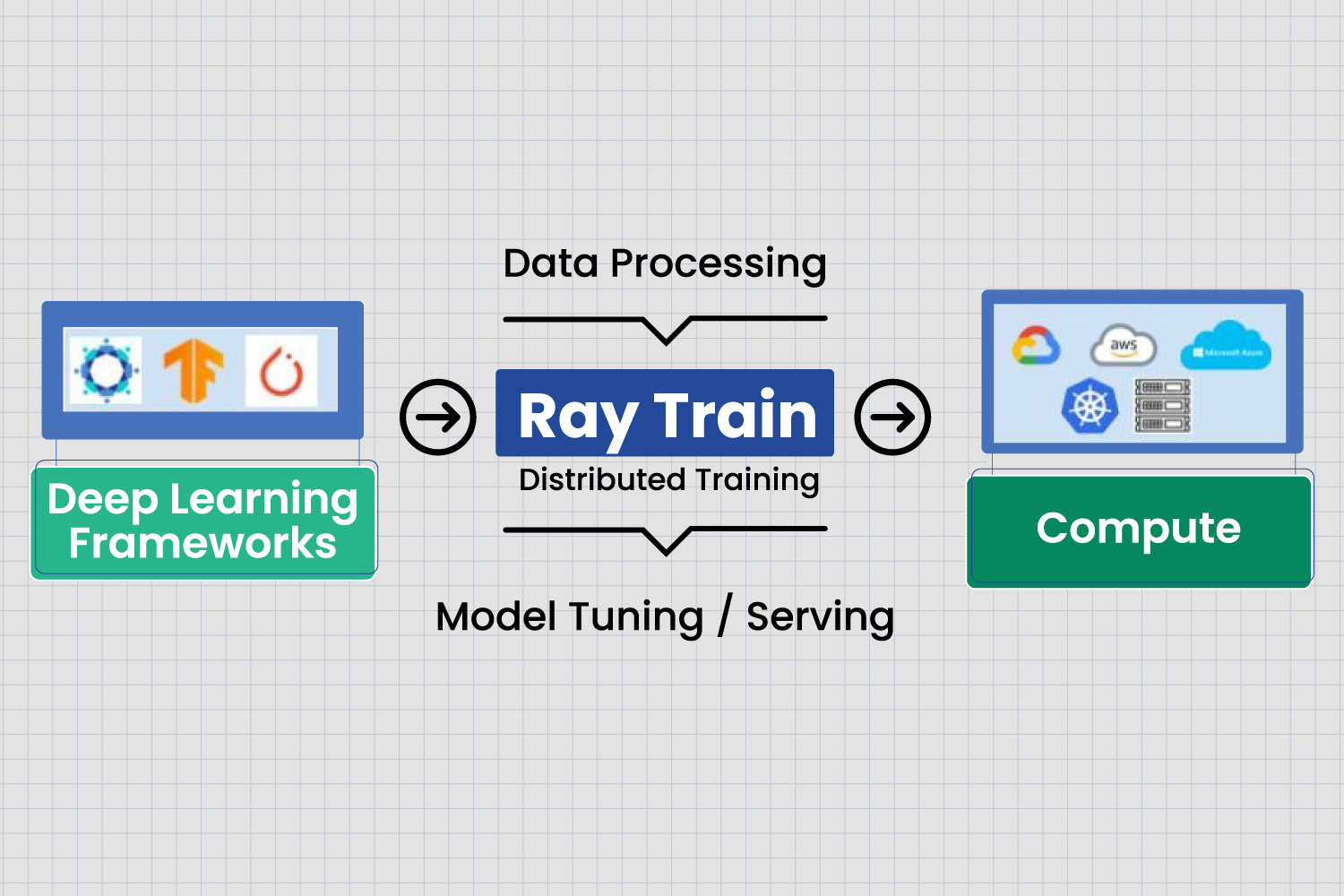
How Ray makes this work
Ray’s approach is mostly about abstraction. Instead of trying to make Apple Silicon and an NVIDIA GPU talk to each other directly, Ray gives you a unified actor model and handles the messy bits underneath.

The pattern I used is the classic parameter server:
- A central coordinator holds the model weights.
- Each worker runs on whatever hardware it has and computes gradients locally.
- Ray collects those gradients and sends them back to the coordinator.
- Ray’s scheduler decides what work goes where.
You write the training code once, and Ray distributes it across whatever hardware is available.
The code
The key annotation is @ray.remote, which turns a regular
Python class into something Ray can run on a remote worker. By
specifying the resource requirements (num_gpus=1,
num_cpus=2), you let the scheduler figure out which machine
each actor lands on:
1 |
|
For the MacBook side, I declared a separate worker class that asks for CPU resources instead of GPU resources, since Ray doesn’t natively schedule on MPS:
1 |
|
The NVIDIA workers land on the CUDA machines, and the CPU/MPS worker ends up on my MacBook because that’s the only machine offering CPU resources without competing for GPUs.
The parameter server
The parameter server holds the canonical model and applies aggregated gradients:
1 |
|
Each worker computes gradients on its own hardware (CUDA, MPS, or CPU) and sends them back. The parameter server averages everything and steps the optimizer.
The training loop
A single training iteration is short:
1 | for iteration in range(training_iterations): |
The ray.get(futures) call is where the cross-machine
coordination happens. Ray takes care of the actual transport between
hosts, and you get the results back as if they were computed
locally.
What I learned
A few things stood out after running this for a while.
It actually works
I had a single model training simultaneously on:
- My MacBook M4 Max (using MPS).
- Mercer’s NVIDIA GeForce GTX TITAN X (using CUDA).
- Crosby’s NVIDIA GeForce GTX TITAN X (using CUDA).
All three machines contributed gradients to the same model in real time, with no hand-rolled glue code between them.
Resource utilization gets a lot better
Instead of letting hardware sit idle because it doesn’t match a “preferred” setup, you can use everything you’ve got. The worst case is roughly the speed of your slowest worker, and even that is better than running nothing.
The parameter server pattern scales
This isn’t only useful as a toy. The parameter server pattern scales to much larger models and clusters. Netflix is using Ray for heterogeneous training clusters with mixed hardware across their infrastructure, which is the same pattern I used here, just much bigger.
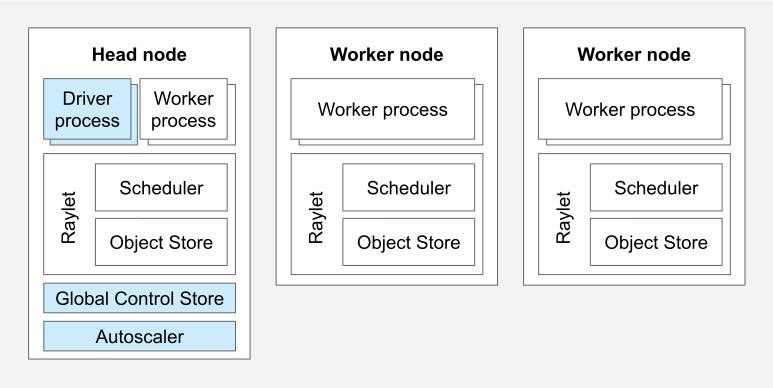
Fault tolerance comes mostly for free
Ray handles worker failures without much help from you. If one machine crashes, training continues with whoever is still alive, and you don’t lose progress.
Why this matters beyond a hobby project
Heterogeneous training matters more than it used to. As models get larger, training cost dominates the budget for a lot of teams, and being locked into a single hardware vendor gets expensive.
Recent work shows that heterogeneous training can be up to 16% more efficient than equivalent homogeneous setups, especially for models past a billion parameters. Companies are starting to treat vendor diversity as a cost optimization problem rather than just a logistical headache.
Scaling to real models
My demo used a tiny network. The same pieces apply at scale, but you have to add a few things on top: memory management with gradient checkpointing and model sharding, better communication backends, and Ray Data for distributed data loading.
For models in the 1B+ parameter range, DeepSpeed integration handles memory pressure, mixed precision speeds up the matmuls, and dynamic batching matches each worker to its hardware budget.
The setup scripts
I wrote two short scripts to make spinning up the cluster reproducible.
setup_cluster.sh:
1 |
|
teardown_cluster.sh:
1 |
|
After that, the MacBook just connects as another worker. No Kubernetes, no Docker orchestration, no SLURM. Ray takes care of the cluster lifecycle and the workload scheduling.
Building a small framework
Once I had this working, it was clear other people probably hit the same problem. So I wrapped the moving parts in a simple framework: distributed-hetero-ml.
The goal was to make heterogeneous distributed training as boring as possible. You define your model and your data, and the framework handles the rest:
1 | from distributed_hetero_ml import DistributedTrainer, TrainingConfig |
The framework detects available hardware and configures itself accordingly. NVIDIA GPUs get CUDA. Apple Silicon gets MPS. Mixed setups get the parameter server pattern. It also handles checkpointing, cluster connections, and resource management, while still letting you drop down to raw Ray when you need to.
Next steps
The next step is taking this to actual language models. Ray Train ships with Hugging Face Transformers integration, so I can hook a 1B parameter model up to whatever hardware is available at RC, plus any cloud GPUs I want to add later.
The full stack would be Ray Data for distributed loading, Ray Train for orchestration, Ray Tune for hyperparameter search, and Ray Serve for deployment. The same parameter-server pattern I’m using on a few machines is what scales those systems out to whole datacenters.
Wrapping up
Ray made it possible to use all the available hardware regardless of vendor. The “this only works on NVIDIA” problem and the “you need identical hardware on every node” problem both go away once you let Ray sit between you and the metal.
Watching my MacBook contribute gradients alongside two NVIDIA machines, all working on the same model in real time, was genuinely satisfying. It also made me notice how much of the hardware-vendor tribalism is unnecessary for the actual research work you want to do.
What started as a “hey, can I use these random GPUs?” question at RC turned into a small framework that hopefully makes this easier for someone else. Being GPU poor really does force you to get creative.