I’d been using TensorFlow for a while without really understanding what was happening behind all the convenient function calls. So I built a small neural network from scratch using only NumPy. The point was to work through the math myself and see if any of it stuck. Michael Nielsen’s book and 3Blue1Brown’s neural network videos helped a lot.
The setup
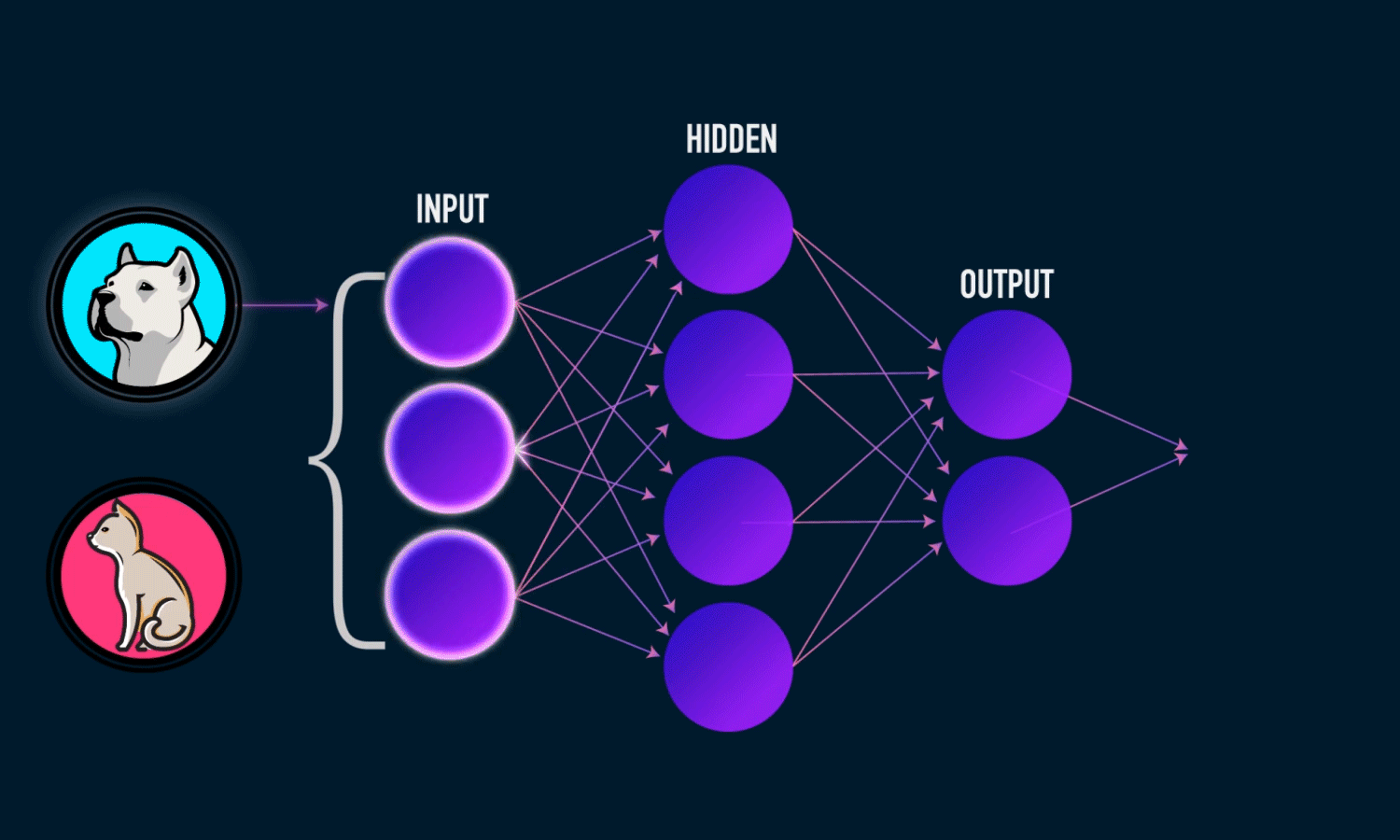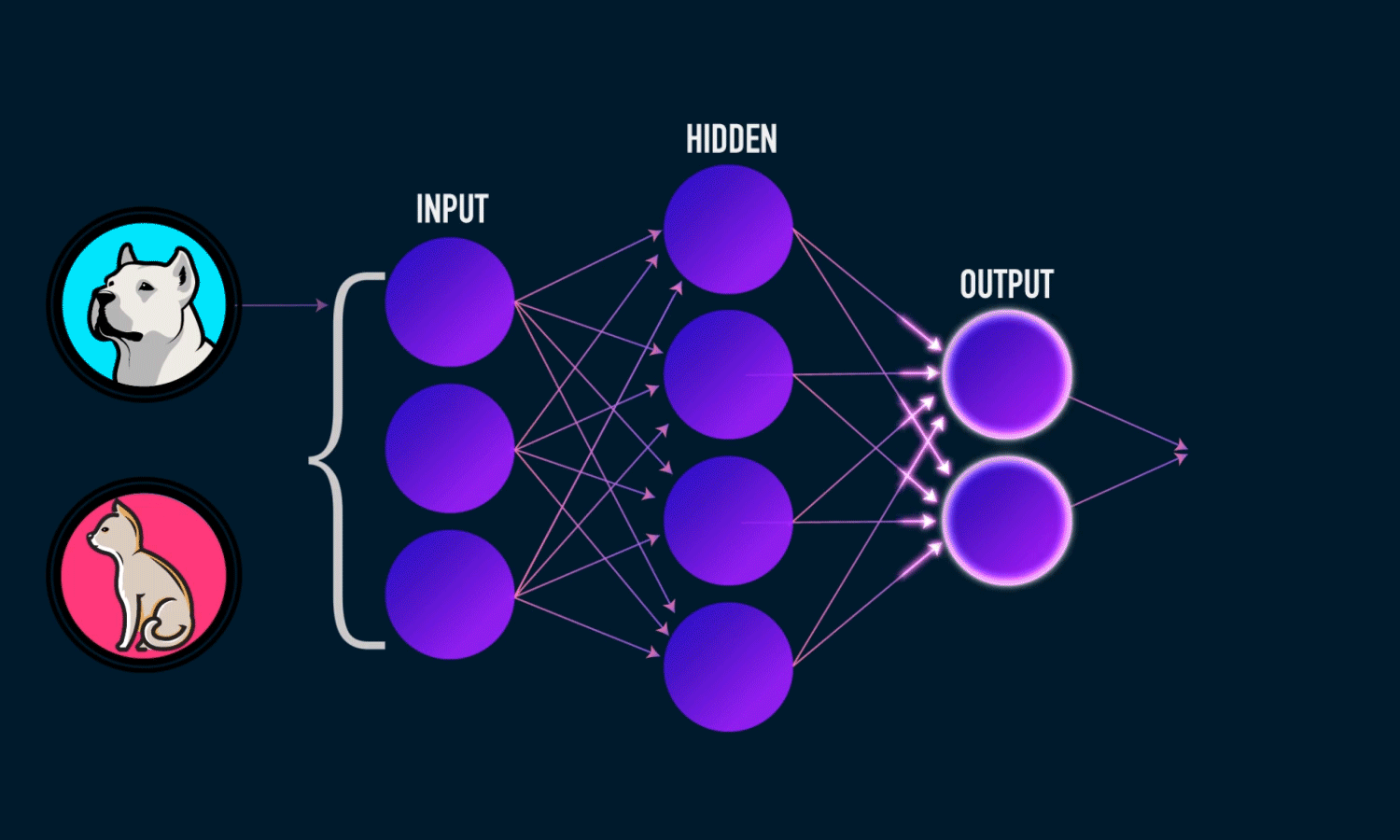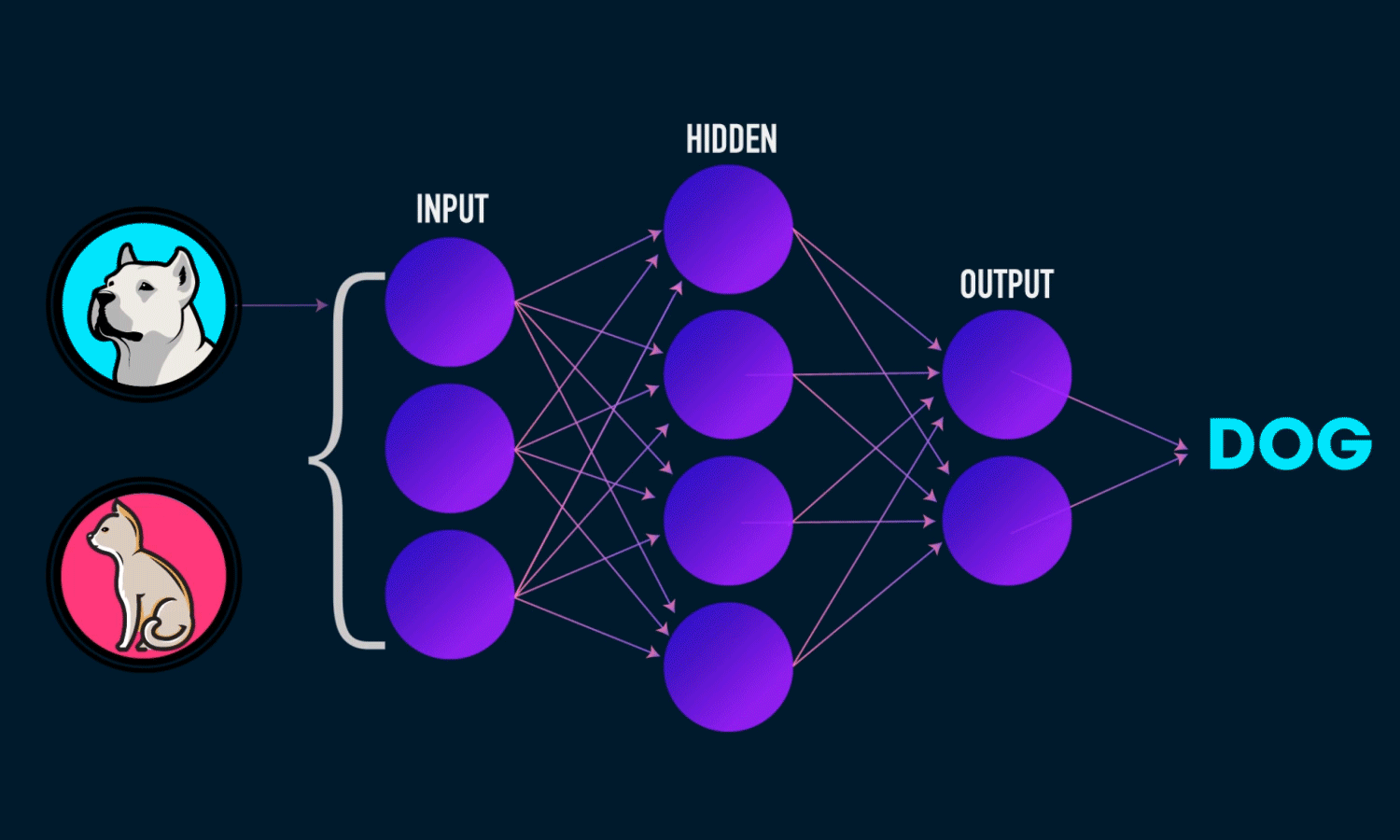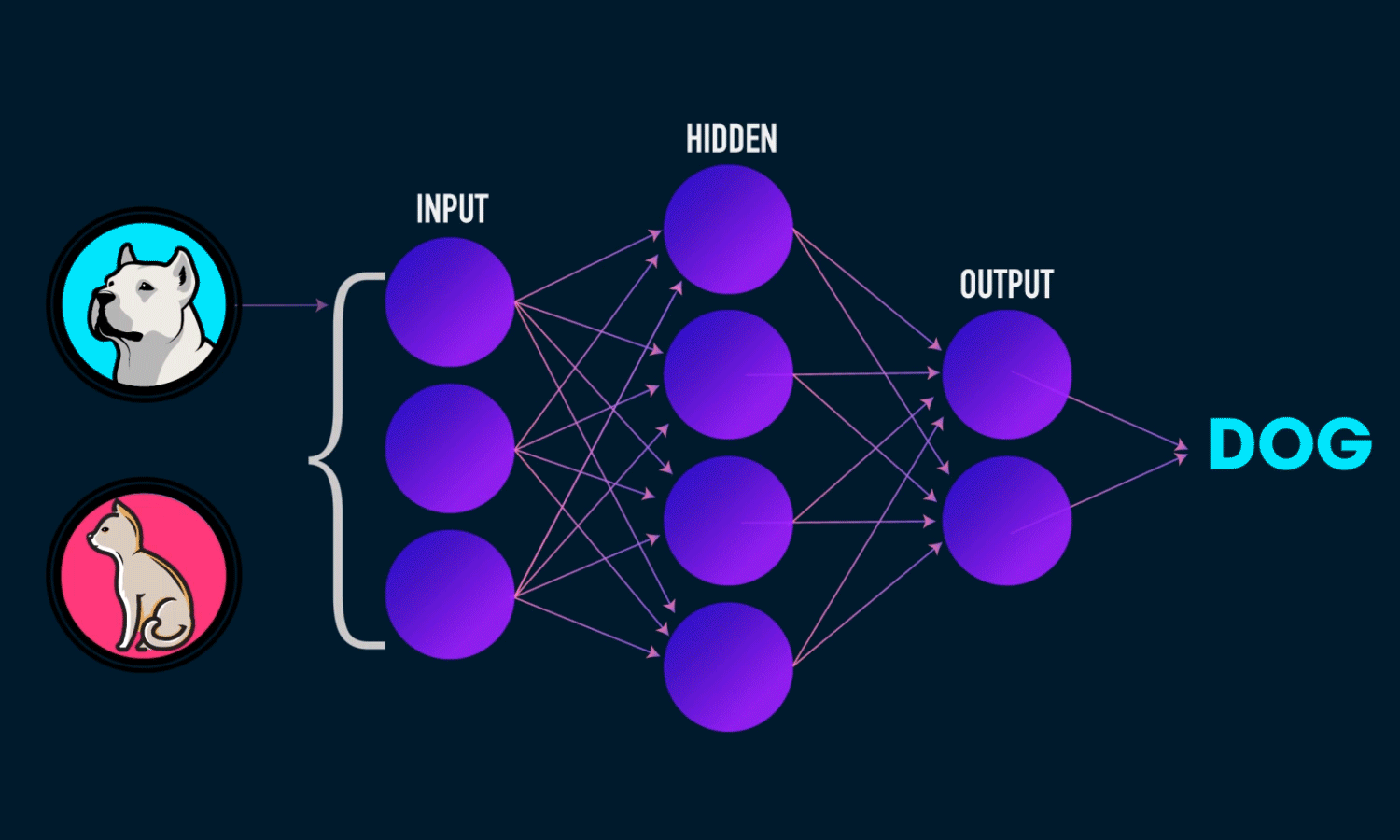
A neural network is a stack of layers, where each layer is a bunch of neurons doing matrix math with a nonlinearity at the end. Each neuron takes some inputs, multiplies them by weights, adds a bias, and outputs a number:
\[z = \sum_{i=1}^{n} w_i x_i + b\]
I went with three layers, sigmoid activations, and binary cross entropy loss. Nothing fancy.
1 | import numpy as np |
Initialization
How you initialize the weights matters more than I expected. Make them too big and the network blows up; too small and it barely learns. Xavier initialization keeps the variance reasonable as activations propagate through layers:
1 | def _initialize_parameters(self) -> dict[str, np.ndarray]: |
Forward pass
This is where you actually run data through the network. The sigmoid squashes the output between 0 and 1:
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]
1 | def forward_propagation(self, X: np.ndarray): |
I cached the intermediate Z and A values
because backprop needs them, and recomputing the forward pass every time
would be wasteful.
Loss
For binary classification I used binary cross entropy. It penalizes confident wrong answers more than uncertain ones, which is the behavior you want from a loss:
\[E = -\frac{1}{m}\sum_{i=1}^m \left[ y_i \log(a_i) + (1 - y_i) \log(1 - a_i) \right]\]
The loss should drop as predictions get better. If it doesn’t, something is wrong upstream.
Backprop
The network learns by figuring out how much each weight contributed to the error and nudging it in the right direction. The chain rule does most of the work:
\[\frac{\partial E}{\partial w_{i}} = \frac{\partial E}{\partial y} \cdot \frac{\partial y}{\partial z} \cdot \frac{\partial z}{\partial w_{i}}\]
Then you update the weights:
\[w_{i} := w_{i} - \alpha \frac{\partial E}{\partial w_{i}}\]
The training loop ties everything together:
1 | def train(self, X, Y, learning_rate: float = 0.1, epochs: int = 1000): |
For the output layer the gradient is straightforward:
\[\frac{\partial L}{\partial z^{[L]}} = A^{[L]} - Y\]
For hidden layers you propagate backwards using the chain rule:
\[\frac{\partial L}{\partial z^{[l]}} = W^{[l+1]T} \frac{\partial L}{\partial z^{[l+1]}} \odot \sigma'(z^{[l]})\]
The implementation walks the layers in reverse:
1 | def _backward_propagation(self, X, Y, cache, learning_rate): |
The sigmoid derivative has a nice closed form, which makes the implementation cleaner: \(\sigma'(z) = \sigma(z)(1 - \sigma(z))\). You already have \(\sigma(z)\) from the forward pass, so the derivative is basically free.
What I got out of it
After this exercise I had way more intuition for what TensorFlow was doing under the hood. Things like “why is my loss exploding to NaN” or “why is my network not learning” stopped feeling like mysteries. They turned into pretty mechanical questions about gradients, initialization, and learning rates.
If you’ve been using ML libraries without ever opening them up, I’d recommend doing this once. It’s tedious, but the intuition you walk away with sticks in a way that no tutorial gives you.