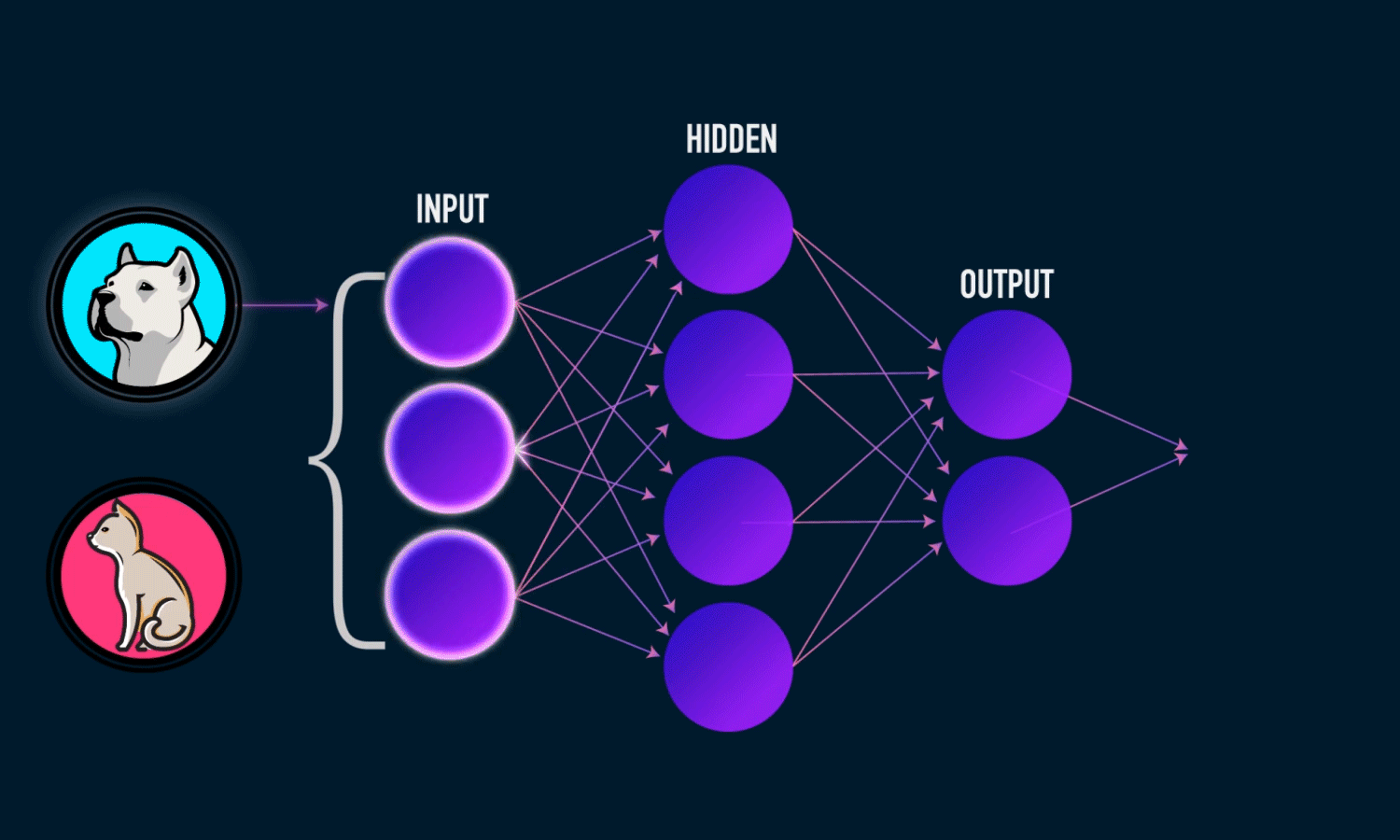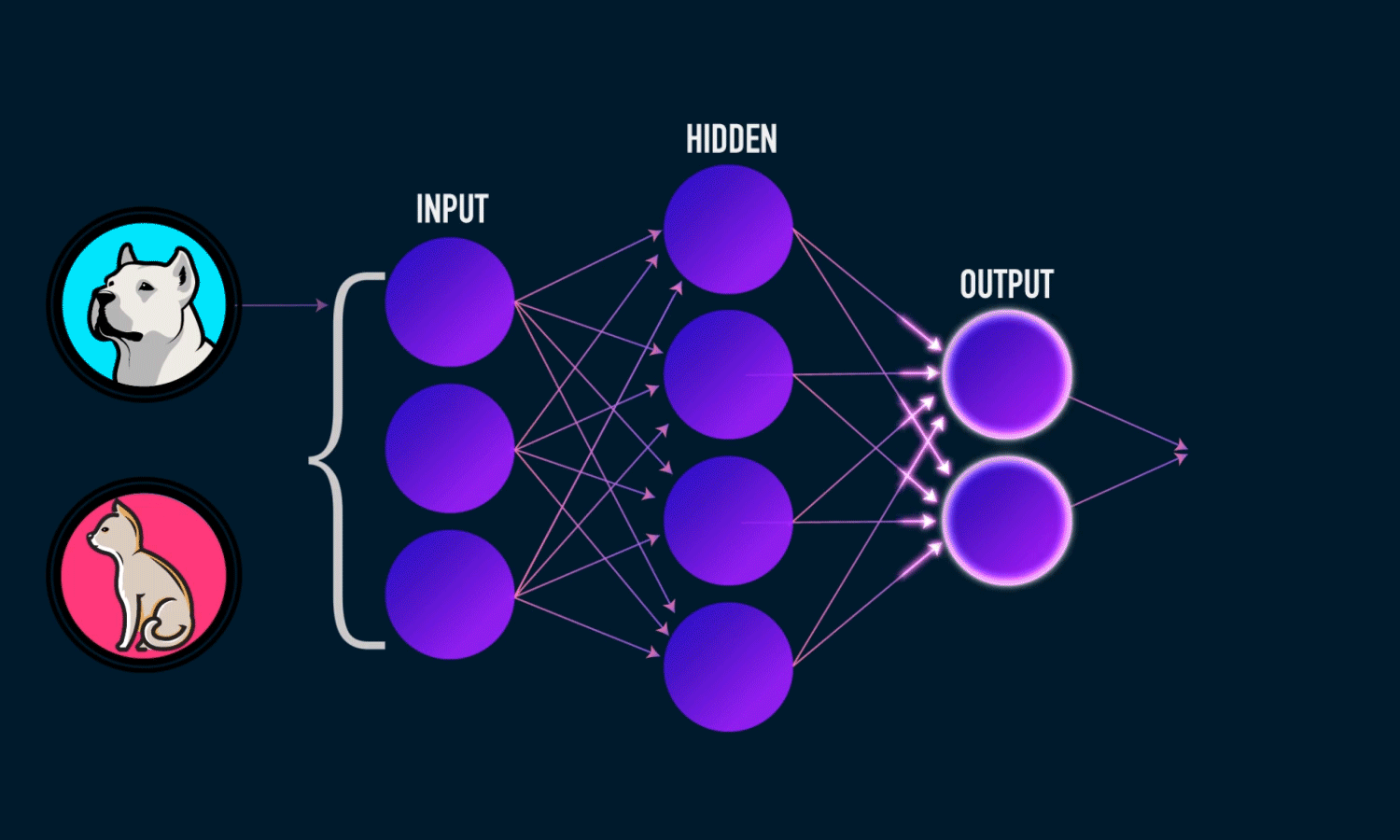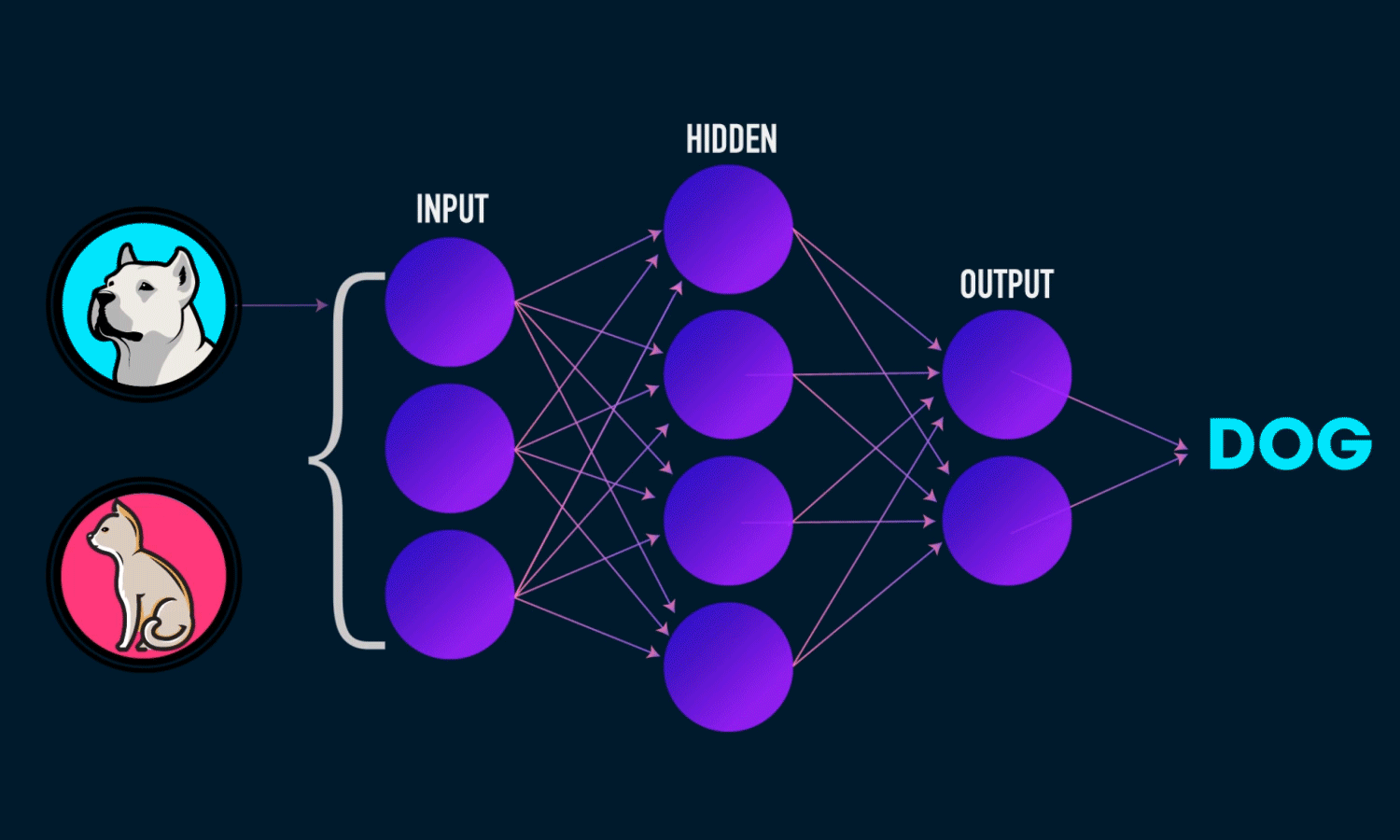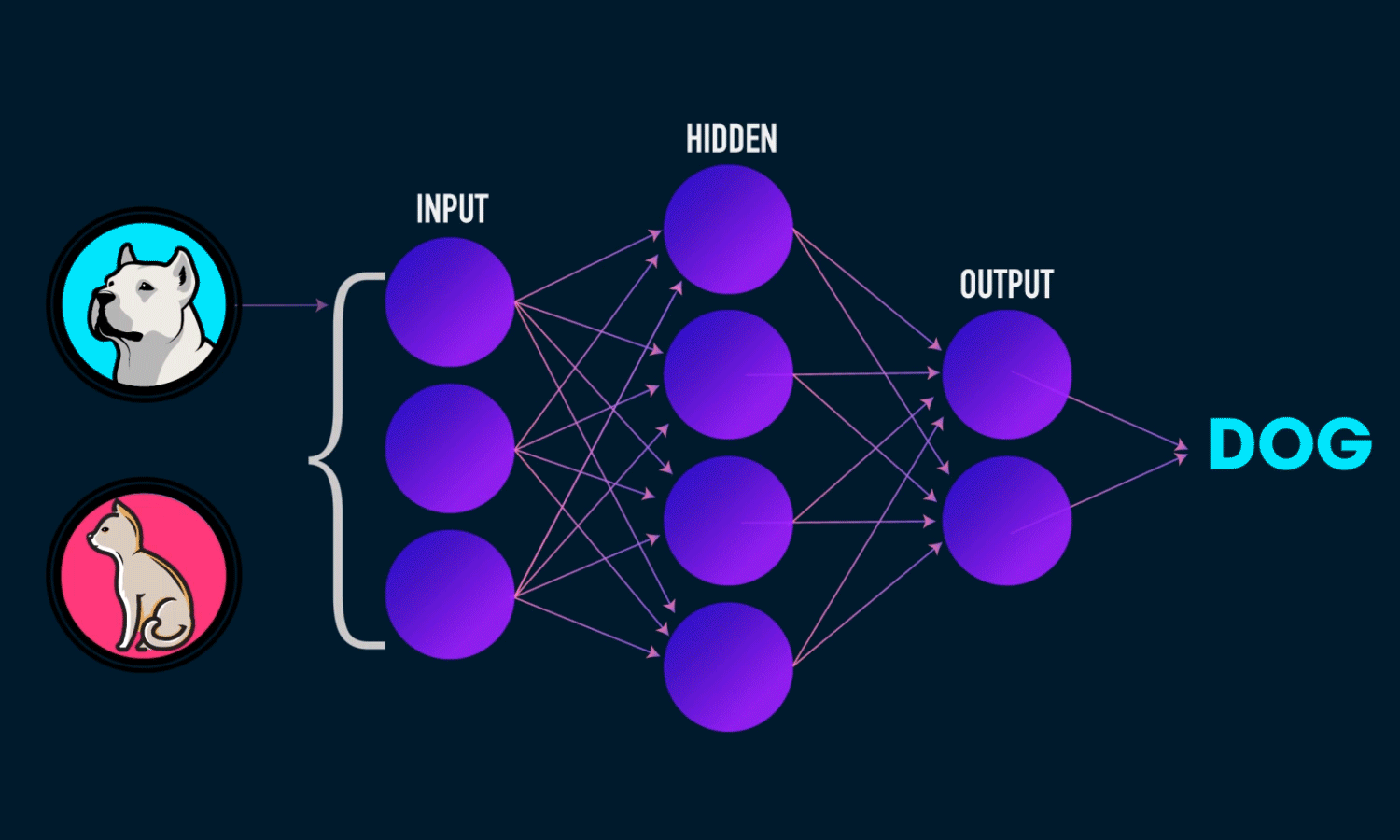
I’d been using TensorFlow for a while, but honestly had no clue what was actually happening behind all those convenient functions. So I decided to build a neural network using just NumPy to really understand the math. Shoutout to Michael Nielsen’s book and 3Blue1Brown’s videos for making the concepts click.
What We’re Building
A neural network is just layers of neurons doing matrix math with some nonlinear functions thrown in. Each neuron takes inputs, multiplies them by weights, adds a bias, and spits out a number:
\[z = \sum_{i=1}^{n} w_i x_i + b\]
Let’s build a simple three layer network to see how this works:
1 | import numpy as np |
Setting Up the Weights
I learned the hard way that how you initialize your weights actually matters a lot. If they’re too big or too small, your network either explodes or barely learns anything. Xavier initialization helps keep things reasonable:
1 | def _initialize_parameters(self) -> dict[str, np.ndarray]: |
Forward Pass
This is where we actually run data through the network. We use the sigmoid function to squash outputs between 0 and 1:
\[\sigma(z) = \frac{1}{1 + e^{-z}}\]
Here’s how that looks in code:
1 | def forward_propagation( |
Measuring How Wrong We Are
For binary classification, we use binary cross entropy loss. It basically punishes confident wrong answers more than uncertain ones:
\[E = -\frac{1}{m}\sum_{i=1}^m \left[ y_i \log(a_i) + (1-y_i) \log(1-a_i) \right]\]
The math looks scary, but the idea is simple: we want our loss to get smaller as our predictions get better.
Learning Through Mistakes
The network learns by figuring out how much each weight contributed to the error, then adjusting accordingly. This uses the chain rule from calculus:
\[\frac{\partial E}{\partial w_{i}} = \frac{\partial E}{\partial y} \cdot \frac{\partial y}{\partial z} \cdot \frac{\partial z}{\partial w_{i}}\]
Once we have these gradients, we update the weights:
\[w_{i} := w_{i} - \alpha \frac{\partial E}{\partial w_{i}}\]
Here’s the training loop:
1 | def train( |
The Backpropagation Algorithm
This is the trickiest part. We work backwards through the network, figuring out how much each parameter contributed to the final error. For the output layer, it’s straightforward:
\[\frac{\partial L}{\partial z^{\[L\]}} = A^{\[L\]} - Y\]
For hidden layers, we need to use the chain rule:
\[\frac{\partial L}{\partial z^{\[l\]}} = W^{\[l+1\]T} \frac{\partial L}{\partial z^{\[l+1\]}} \odot \sigma'(z^{\[l\]})\]
Here’s the implementation:
1 | def _backward_propagation( |
The gradients for weights and biases work out to:
\[\frac{\partial L}{\partial W^{\[l\]}} = \frac{1}{m} \frac{\partial L}{\partial z^{\[l\]}} A^{\[l-1\]T}\]
\[\frac{\partial L}{\partial b^{\[l\]}} = \frac{1}{m} \sum_{i=1}^m \frac{\partial L}{\partial z_{i}^{\[l\]}}\]
A few implementation notes
The gradient calculations work on entire batches at once, which makes everything faster. We also save the intermediate values during the forward pass so we don’t have to recalculate them later. One thing that makes the math nicer is that the derivative of sigmoid has a really clean form: \(\sigma'(z) = \sigma(z)(1-\sigma(z))\).
The network keeps doing forward passes to make predictions, then backward passes to learn from mistakes. Over time, it gets better at whatever you’re training it on. Building this from scratch really helped me understand what all those TensorFlow functions were actually doing. If you want to know what’s happening under the hood, it’s worth the effort.