I spent way too much time during my bachelor thesis diving into federated learning, and it ended up being more interesting than I expected. The basic idea is simple: what if we could train machine learning models without actually collecting everyone’s data in one place? You can, and there are some clever ways to make it secure too. I wrote about what I learned while building my own implementation and writing my thesis.
What’s Federated Learning?
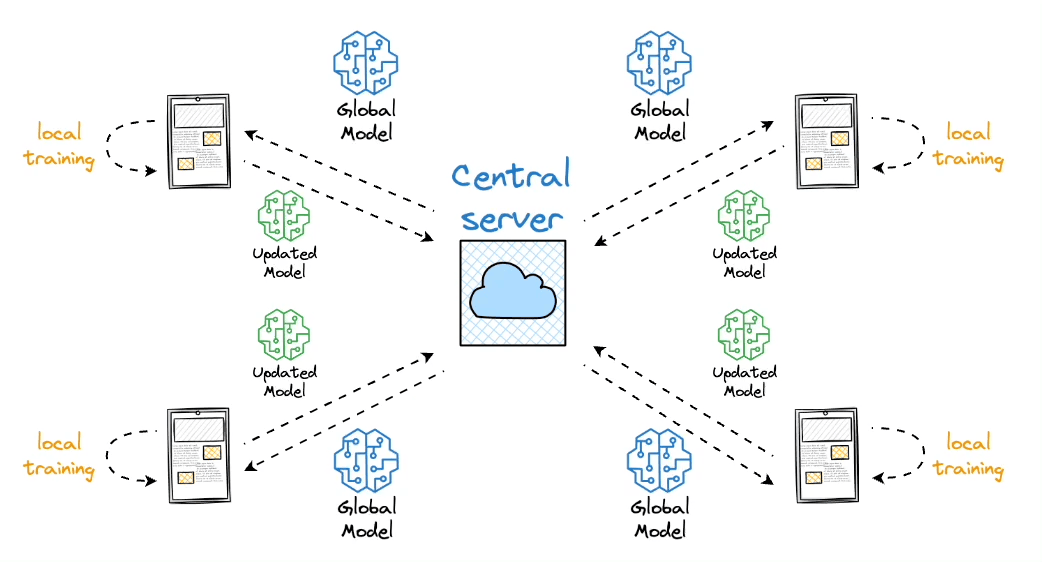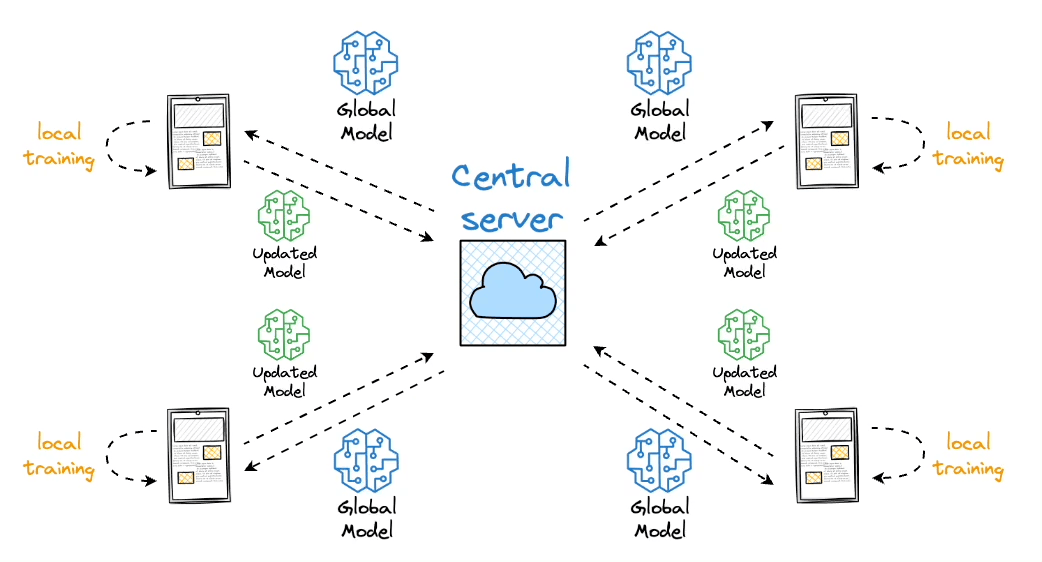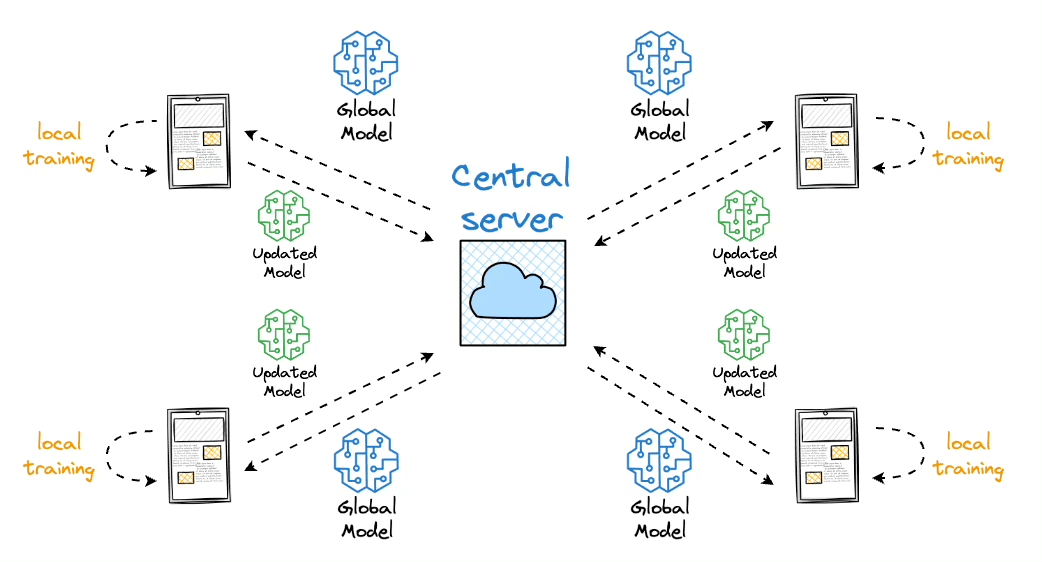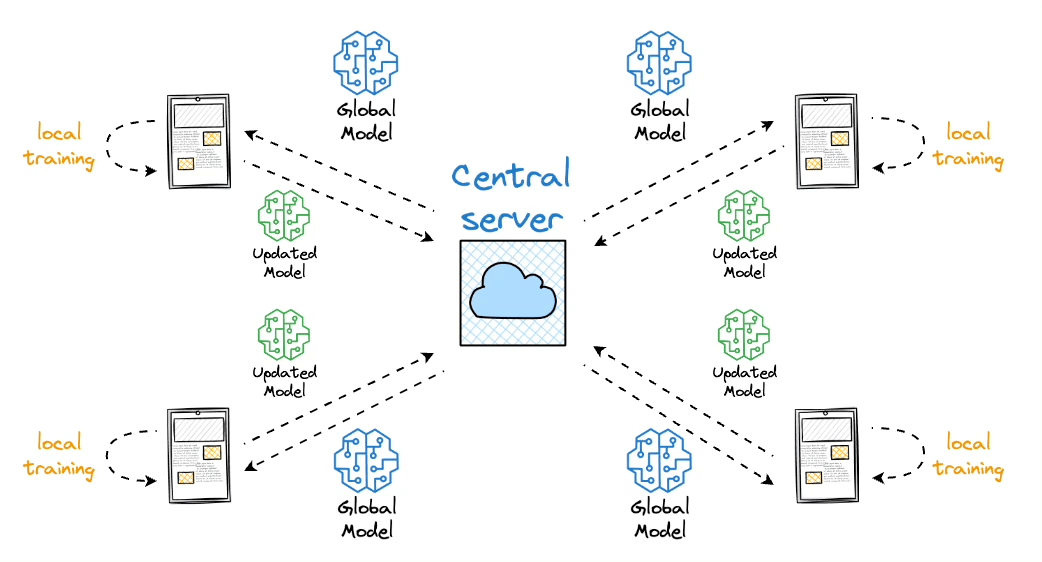
Usually when you train a model, you grab data from everywhere, dump it in one database, and train on that. Federated learning flips this around. Instead of moving data to the model, you move the model to where the data lives. Each device keeps its own data and just sends back what it learned.
The math looks like this: normally you’d minimize some loss function across all your data:
\[\min_{w \in \mathbb{R}^d} F(w) = \frac{1}{N} \sum_{i=1}^N \ell(x_{i}, y_{i}; w)\]
But with federated learning, you split this across different clients:
\[F(w) = \sum_{k=1}^K \frac{n_{k}}{n_{\text{total}}} F_{k}(w)\]
where each client \(k\) has its own local loss \(F_k\) with \(n_k\) data points.
The process works like this: 1. Send the current model to all clients 2. Each client trains on their local data for a bit 3. Clients send back their updates (not their data) 4. Server combines all the updates into a new global model
This keeps data private while still getting the benefits of training on lots of data.
Basic Aggregation Methods
FedSGD
The simplest approach is FedSGD. Everyone does one gradient step and sends their gradient back:
\[w^{t+1} = w^t - \eta \sum_{k=1}^K \frac{n_{k}}{n_{\text{total}}} \nabla F_{k}(w^t)\]
This works but requires a lot of communication since you’re sending gradients after every single step.
FedAvg
FedAvg is way more practical. Let each client train for several rounds locally, then just average their models:
\[w^{t+1} = \sum_{k=1}^K \frac{n_{k}}{n_{\text{total}}} w_{k}^t\]
This cuts down communication dramatically and usually works just as well, though it can struggle when different clients have very different data.
Dealing with Bad Actors
One problem with federated learning is that some clients might send garbage updates, either by accident or on purpose. The simple averaging approach breaks down when you have outliers.
Geometric Median Aggregation
Instead of taking the arithmetic mean, you can use the geometric median, which is much more robust to outliers. You’re trying to find the point that minimizes the sum of distances to all client updates:
\[\min_{z} \sum_{k=1}^m \alpha_{k} \|w_{k} - z\|\]
You solve this iteratively using something like the Weiszfeld algorithm:
\[z^{(i+1)} = \frac{\sum_{k=1}^m \beta_{k}^{(i)} w_{k}}{\sum_{k=1}^m \beta_{k}^{(i)}}, \text{ where } \beta_{k}^{(i)} = \frac{\alpha_{k}}{\max\{\nu, \|w_{k} - z^{(i)}\|\}}\]
The math automatically gives less weight to updates that are far from the center, which helps filter out malicious or buggy clients.
Adding Differential Privacy
Even if clients only send gradients, a sneaky server might still be able to figure out things about the training data by analyzing those gradients carefully. Differential privacy fixes this by adding noise in a specific way.
The Core Idea
Differential privacy says that if you change one person’s data in the dataset, the output shouldn’t change much. Formally, a mechanism is \((\epsilon,\delta)\) differentially private if:
\[\Pr(\mathcal{M}(D) \in S) \leq e^\epsilon \Pr(\mathcal{M}(D') \in S) + \delta\]
for any two datasets \(D\) and \(D'\) that differ by one record.
Making Federated Learning Private
In DP FedAvg, each client does two things before sending their gradient:
Clip the gradient to a maximum norm: \[\tilde{g}_{k} = \frac{g_{k}}{\max(1, \frac{\|g_{k}\|_{2}}{C})}\]
Add Gaussian noise: \[\hat{g}_k = \tilde{g}_k + \mathcal{N}(0, \sigma^2C^2\mathbf{I})\]
The implementation is straightforward:
1 | import numpy as np |
Now even if someone intercepts the gradients, they’re seeing a noisy version that doesn’t reveal much about individual data points.
Homomorphic Encryption
Differential privacy limits what you can infer from gradients, but homomorphic encryption goes further: the server never sees the actual gradients at all, only encrypted versions.
How It Works
Homomorphic encryption lets you do math on encrypted data. If you have encrypted values \(Enc(a)\) and \(Enc(b)\), you can compute:
\[Enc(a) \oplus Enc(b) = Enc(a + b)\]
without ever decrypting them.
For federated learning: 1. Each client encrypts their update: \(c_{k} = \text{Enc}(w_{k})\) 2. Server adds the encrypted updates: \(c_{\text{sum}} = \sum_{k=1}^K c_{k}\) 3. Someone with the private key decrypts the sum: \(\text{Dec}(c_{\text{sum}}) = \sum_{k=1}^K w_{k}\)
In code, this looks like:
1 | from typing import Any, Protocol |
Putting It All Together
A complete federated learning round with differential privacy looks like this:
1 | import numpy as np |
Real World Challenges
A few things I ran into while implementing this:
Non IID data is the biggest pain point. In the real world, different clients have totally different data distributions. Your phone’s photos look nothing like mine, which breaks a lot of the mathematical assumptions.
Client dropout happens constantly. Phones go offline, people close apps, connections fail. Your aggregation strategy needs to handle partial participation gracefully.
Privacy vs accuracy tradeoffs are real. Adding noise helps privacy but hurts model performance. Encrypting everything adds computational overhead. You’re constantly balancing security against practicality.
What stuck with me
The theory behind federated learning is straightforward, but the engineering is where it gets messy. Differential privacy and homomorphic encryption sound intimidating with all the Greek letters, but once you strip away the notation, the core ideas are not that complicated.
What I found most interesting was seeing how all these techniques layer together. You can combine robust aggregation with differential privacy and homomorphic encryption to handle both malicious clients and untrustworthy servers. Getting all of that to work in practice took way more debugging than I expected.
If you want to dig deeper, check out my thesis and the code.