
A friend and I were arguing about what happens when you buy something online and the payment fails halfway through. Where exactly does your money go in the half-second before the dust settles? We ended up reading about transactional protocols and decided we’d learn more by building one than by reading about it. The result was a small two-phase commit system, with the coordinator written in Rust and the microservices in Go.
The basic idea
Two-phase commit (2PC) is a voting protocol for distributed transactions. Either everyone agrees to do something, or nobody does. The classic analogy is picking a restaurant with friends: if anyone vetoes, the whole group has to start over.
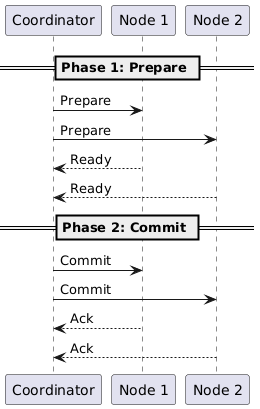
What we built
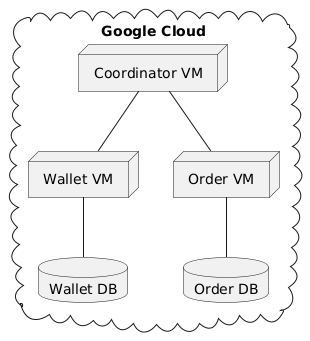
We split the system into three pieces. A coordinator in Rust ran the protocol, a wallet service in Go held user balances, and an order service (also in Go) managed inventory. The two services represent the kind of operation you’d expect to be transactional: charge the user and reserve the item, or do neither.
The coordinator
The coordinator drives the protocol. The two phases (prepare and commit) are pretty literal in code:
1 | struct Coordinator { |
In the prepare phase the coordinator asks each participant whether it’s ready to commit. If anyone says no, or fails to respond in time, the transaction is aborted. If everyone says yes, the coordinator moves into the commit phase and tells them all to make their changes durable.
The microservices
Each microservice does the local work for its part of the transaction. Here’s the wallet service handling a prepare:
1 | type WalletService struct { |
The trick is that the prepare phase locks the relevant rows but doesn’t actually commit the local transaction. The commit only happens after the coordinator gives the go-ahead.
What goes wrong, and there’s a lot
The interesting parts of distributed systems are the failure modes:
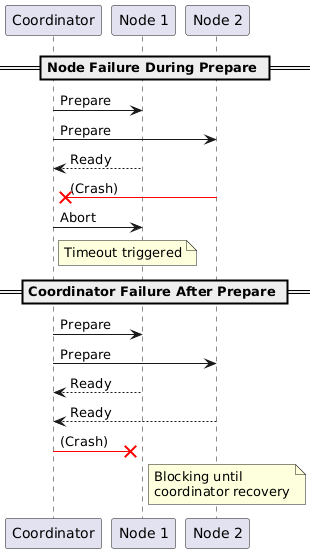
We wrote tests for nodes crashing mid-protocol, networks dropping packets, and services getting too slow to answer in time. Distributed systems fail in creative ways.
The downsides of 2PC
Two-phase commit solves the consistency problem, but you pay for it. Every participant blocks until the coordinator decides. The protocol is chatty. And if the coordinator dies between the prepare and commit phases, everyone is stuck waiting on a decision that may never come. That last failure mode is the reason most modern systems prefer protocols with built-in coordinator recovery, like Raft or Paxos-based commit, or sidestep the problem entirely with sagas.
Running it on real infrastructure
We deployed everything on Google Cloud, with each service on its own VM. That’s where we learned how different real networks are from localhost.
The prepare phase that completed in microseconds locally took milliseconds across regions, and the long tail was much worse than the median. Failures stopped being binary and started being a spectrum: a slow response is hard to distinguish from a dead node, and the coordinator has to make timeout decisions that are always going to be a little wrong.
Testing was the hard part
Testing distributed systems is harder than testing regular code. Things happen out of order, partial failures look like successes from one side, and timing matters in ways it usually doesn’t:
1 |
|
You end up writing a lot of fault-injection tests, simulating crashes and slow responses, just to be sure the protocol does the right thing when reality misbehaves.
What we got out of it
Rust’s ownership model paid off in places where the protocol’s state was easy to mess up. The compiler caught a few bugs that would have been ugly to track down at runtime. Go’s goroutines made it easy to handle multiple concurrent transactions without much ceremony.
The bigger lesson was just how different real infrastructure is from localhost. Networks fail constantly, latencies are bursty, and any assumption you make about timing will eventually be wrong. Reading about distributed systems is useful, but you don’t really understand them until you watch one of your services time out for the first time because of a transient packet loss.
The code is on GitHub if you want to look through it. The README is in Norwegian since it was originally a class project.