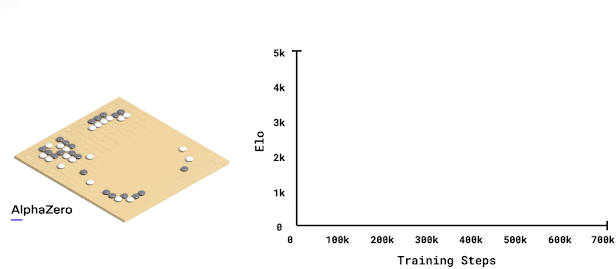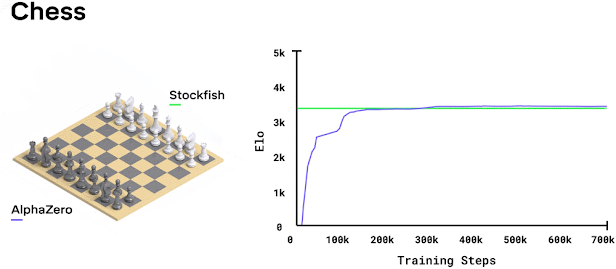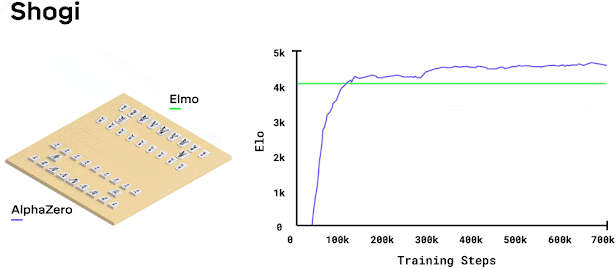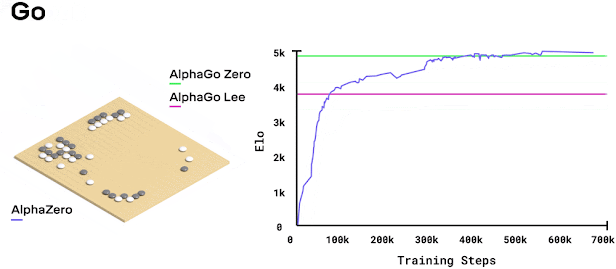
While I was at Cogito NTNU, I decided to implement AlphaZero from scratch with a few teammates. I assumed this would be a few weekends of work, since the paper looks clean and the algorithm fits on a single slide. It ended up being months of debugging and optimization. Research papers tend to skip over the implementation details that turn out to be most of the actual work.
How AlphaZero works
AlphaZero combines Monte Carlo tree search with a neural network that predicts two things: which moves are good (a policy) and who’s winning the position (a value). The training loop is conceptually simple:
- Self-play to generate training data.
- Train the neural network on that data.
- Test whether the new network beats the previous one.
The network outputs a policy vector \(\pi\) over moves and a value \(v \in [-1, 1]\) for how good the position looks. The policy and value heads share a convolutional trunk:
1 | import torch |
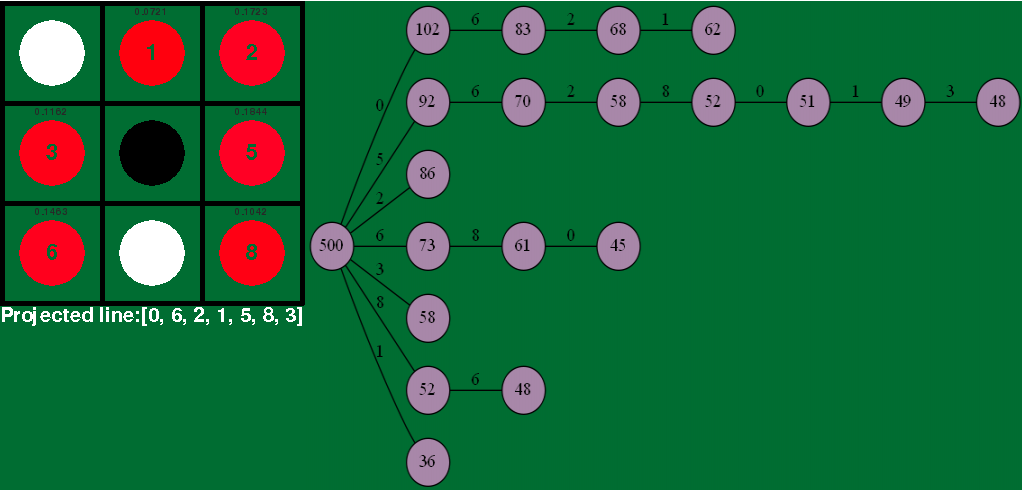 A snapshot of our MCTS
implementation on a Tic-Tac-Toe board, with the search tree on the right
showing visit counts per node, starting from 500 at the root.
A snapshot of our MCTS
implementation on a Tic-Tac-Toe board, with the search tree on the right
showing visit counts per node, starting from 500 at the root.
The loss function
The network learns by minimizing a single combined loss:
\[L = (z - v)^2 - \pi^T \log p + c\|\theta\|^2\]
where \(z\) is the actual game outcome, \(v\) is the network’s predicted value, \(\pi\) is the move distribution from MCTS, \(p\) is the network’s predicted policy, and the last term is L2 regularization to keep the weights from running away.
Making it fast
Getting the algorithm right was about half the work. Getting it to run at a useful speed required engineering tricks the paper doesn’t bother with.
The biggest single win was running MCTS simulations in parallel and batching the network evaluations:
1 | import torch.multiprocessing as mp |
The network is the bottleneck, and sending one position at a time wastes most of the GPU. Batching turned a slow training loop into a usable one.
The other obvious win was caching. Self-play games revisit the same positions a lot, especially in the opening:
1 | import numpy as np |
Results
Once parallel MCTS, batched evaluations, and the position cache were in place, the numbers improved across the board:
- Self-play got 3.2× faster.
- Training was 2.8× faster.
- Memory usage dropped by 45%.
We also tried path consistency optimization, which forces value predictions to stay consistent along search paths:
\[L_{PC} = \|f_v - \bar{f}_v\|^2\]
It made the network learn faster, although I’m still not entirely sure why it helps as much as it does.
What I’d say to anyone trying this
Implementing research papers is harder than it looks. The papers make everything sound clean because they have to fit in eight pages. The actual work is in the parts that don’t get written down: how you batch, how you cache, how you handle the long tail of edge cases that come up in self-play.
Most of the speed gap between “the paper says” and “what we measured” came from those details. Some of them really are obvious to the authors, and some of them are obvious only after you’ve spent a week debugging your own implementation.
The code is on GitHub if you want to look through it.